SPARQL
L’ambition de SPARQL est d’offrir une interopérabilité, non seulement au niveau des services, comme avec les services Web, mais aussi au niveau des données, structurées ou non, qui sont disponible à travers l’Internet. Toutes ces données disponibles en ligne via SPARQL sont ce que l’on nomme le Web des données1.

La structure d’une requête SPARQL2
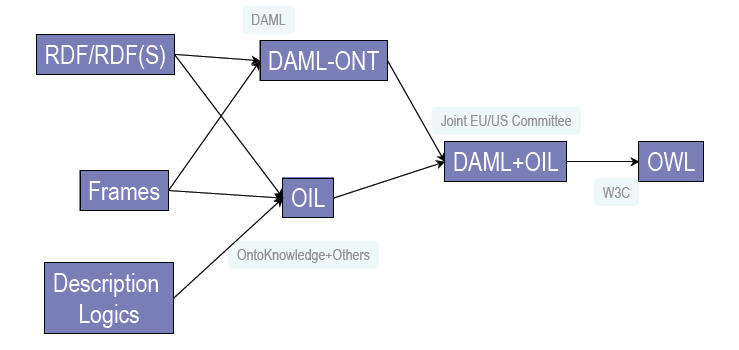
Les objets sur l’Internet sont liées l’un à l’autre. Avec des triplets RDF, il est possible de décrire le lien entre différents objets sous la forme de (sujet, prédicat, objet). Ces connexions peuvent être représentés sous forme de graphe des objets, où chaque noeud est un objet et chaque bord est une propriété. Avec SPARQL (SPARQL Protocole et RDF Query Language), il est possible de créer des requêtes basées sur ces graphes. La structure d’une requête SPARQL est indiqué dans la figure.
Dans l’exemple ci-dessous, une requête SPARQL est affiché. Nous voudrions sélectionner les personnes et leurs âges de l’ensemble de données http://example.org/data.rdf. La structure de l’exécution est représentée dans la figure.

La structure de l’exécution de SPARQL3
Requêtes fédérées
Il est possible, qu’un objet existe sur Internet dans plus de graphe avec des URI différents, donc il peut être difficile de recueillir toutes les informations existantes sur cet objet. La raison pour cela est de certaines informations peuvent être trouvées dans une graphe et quelques autres informations peuvent être trouvées dans l’autre graphe. Pour résoudre ce problème, nous avons besoin de créer des requêtes fédérées. Dans cette manière, c’est possible de créer une requête en utilisant plusieurs ensembles de données, en d’autres termes plusieurs graphe.
C’est aussi facile de vérifier si deux objets de différents ensembles de données sont liées, ou bien la même entité. Avec les requêtes fédérées, on peut obtenir toutes les informations à partir d’une seule requête. Pour ce faire, nous devons faire les étapes suivantes4 :
- Utiliser un service des requêtes fédérées (médiateur). Nous exécutons la requête à travers ce médiateur.
- Le médiateur crée des sous-requêtes vers tous les points de terminaison SPARQL dans notre requête.
- Le médiateur reçoit les réponses des points de terminaison différents et les combine pour obtenir la résultat de requête fédérée.
La structure d’une requête fédérée est représentée dans la figure.

La structure d’une requête fédérée5
Notre travail
Dans notre projet, nous voulions créer une requête qui renvoie les films de l’acteur Tom Hanks à partir de la base de données de Linkedmdb et qui renvoie des informations supplémentaires (par exemple sa date de naissance) du même objet d’une autre base de données, Dbpedia.
En premier temps, nous avons téléchargé Jena à partir de https://jena.apache.org/ et nous avons créé un nouveau projet dans Eclipse pour créer une requête fédérée. La première étape était d’importer les bibliothèques de Jena au chemin de construction (“build path”) de notre projet. Ensuite, nous avons créé une classe SimpleFederatedQuery. Dans cette classe, nous n’avions qu’une seule variable statique et la fonction main. Cette variable statique était une chaîne (http://sparql.org/sparql), qui représente en fait le médiateur nous utilisions. Dans la fonction main nous avons créé la requête SPARQL basée sur le tutoriel SPARQL de Jena6. La première requête que nous avons créé est le suivant:
String queryString = "PREFIX imdb: <http://data.linkedmdb.org/resource/movie/> "
+ "PREFIX dbpedia: <http://dbpedia.org/ontology/> "
+ "PREFIX dcterms: <http://purl.org/dc/terms/> "
+ "PREFIX owl: <http://www.w3.org/2002/07/owl#>"
+ "SELECT * "
+ " from <http://xmlns.com/foaf/0.1/> "
+ " { "
+ " SERVICE <http://data.linkedmdb.org/sparql> "
+ " { "
+ " ?actor1 imdb:actor_name \"Tom Hanks\". "
+ " ?movie imdb:actor ?actor1 ; "
+ " dcterms:title ?movieTitle . "
+ " } "
+ " SERVICE <http://dbpedia.org/sparql> "
+ " { "
+ " ?actor owl:sameAs ?actor1 ; "
+ " dbpedia:birthDate ?birth_date . "
+ " } "
+ " } ";
Après avoir exécuté cette requête à partir d’Eclipse, la sortie était “HTTP 503 error making the query: The query timed out (restricted to 10000,60000 ms)”. Pour trouver le problème, nous avons dû consulter la page Dbpedia de Tom Hanks–http://dbpedia.org/page/Tom_Hanks. Sur cette page, nous avons pu voir qu’il y avait un seul lien vers Linkedmdb avec la balise sameAs, qui était http://data.linkedmdb.org/resource/producer/9810. Cependant, ce lien n’est pas Tom Hanks comme un acteur, mais Tom Hanks comme un producteur. Pour cette raison, nous avons modifié la requête sur linkedmdb de imdb:actor_name et imdb:acteur à imdb:producer_name et imdb:producer respectivement. La requête est devenue la suivante:
String queryString = "PREFIX imdb: <http://data.linkedmdb.org/resource/movie/> "
+ "PREFIX dbpedia: <http://dbpedia.org/ontology/> "
+ "PREFIX dcterms: <http://purl.org/dc/terms/> "
+ "PREFIX owl: <http://www.w3.org/2002/07/owl#>"
+ "SELECT * "
+ " from <http://xmlns.com/foaf/0.1/> "
+ " { "
+ " SERVICE <http://data.linkedmdb.org/sparql> "
+ " { "
+ " ?actor1 imdb:producer_name \"Tom Hanks\". "
+ " ?movie imdb:producer ?actor1 ; "
+ " dcterms:title ?movieTitle . "
+ " } "
+ " SERVICE <http://dbpedia.org/sparql> "
+ " { "
+ " ?actor owl:sameAs ?actor1 ; "
+ " dbpedia:birthDate ?birth_date . "
+ " } "
+ " } ";
Après ce changement, dans la sortie de notre requête, nous avons pu obtenir ce que nous voulions. L’actor, le movie et le movieTitle sont venus de Dbpedia et le même actor et son anniversaire sont venus de Linkedmdb. En d’autres termes, nous avons créé une requête fédérée, qui utilisait deux bases de données différentes et qui a trouvé les différentes informations sur le même objet.
Le résultat final que nous avons obtenu :
log4j:WARN No appenders could be found for logger (org.apache.jena.riot.system.stream.JenaIOEnvironment). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Results from query: ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | actor1 | movie | movieTitle | actor | birth_date | ================================================================================================================================================================================================================================================= | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/38203> | "Cast Away" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/38695> | "Band of Brothers" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/39389> | "My Big Fat Greek Wedding" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/1492> | "Looney Tunes: Back in Action" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/40586> | "Connie and Carla" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/42002> | "House of D" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/43580> | "Evan Almighty" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/44738> | "The Ant Bully" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/45166> | "Starter for Ten" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/5399> | "Charlie Wilson's War" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/5495> | "Where the Wild Things Are" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/5516> | "The Polar Express" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/45816> | "The Great Buck Howard" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/50695> | "My Life In Ruins" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/11531> | "Mamma Mia!" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/51110> | "The Pacific" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/18755> | "City of Ember" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/23012> | "Surfer Dude" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | | <http://data.linkedmdb.org/resource/producer/9810> | <http://data.linkedmdb.org/resource/film/52882> | "The Ant Bully" | <http://dbpedia.org/resource/Tom_Hanks> | "1956-07-09+02:00"^^<http://www.w3.org/2001/XMLSchema#date> | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- All done.
Notre code est le suivant :
package WebSemantic;
import com.hp.hpl.jena.query.Query;
import com.hp.hpl.jena.query.QueryExecution;
import com.hp.hpl.jena.query.QueryExecutionFactory;
import com.hp.hpl.jena.query.QueryFactory;
import com.hp.hpl.jena.query.ResultSet;
import com.hp.hpl.jena.query.ResultSetFormatter;
/**
*
* @author Lisa MALIPHOL, Romy ARDIANTO, Andres RAMIREZ GOMEZ, Sami ALKABBANI, András PÁSZTOR
*
* Federated query using two different sources
* Example taken from here :
* http://answers.semanticweb.com/questions/9190/federated-sparql-query-using-jena
*
*/
public class SimpleFederatedQuery {
final static String serviceEndpoint = "http://sparql.org/sparql";
public static void main(String[] args) {
String queryString = "PREFIX imdb: <http://data.linkedmdb.org/resource/movie/> "
+ "PREFIX dbpedia: <http://dbpedia.org/ontology/> "
+ "PREFIX dcterms: <http://purl.org/dc/terms/> "
+ "PREFIX owl: <http://www.w3.org/2002/07/owl#>"
+ "SELECT * "
+ " from <http://xmlns.com/foaf/0.1/> "
+ " { "
+ " SERVICE <http://data.linkedmdb.org/sparql> "
+ " { "
+ " ?actor1 imdb:producer_name \"Tom Hanks\". "
+ " ?movie imdb:producer ?actor1 ; "
+ " dcterms:title ?movieTitle . "
+ " } "
+ " SERVICE <http://dbpedia.org/sparql> "
+ " { "
+ " ?actor owl:sameAs ?actor1 ; "
+ " dbpedia:birthDate ?birth_date . "
+ " } "
+ " } ";
Query query = QueryFactory.create(queryString); // exception happens
// here
QueryExecution qe = QueryExecutionFactory.sparqlService(serviceEndpoint, query);
try {
ResultSet rs = qe.execSelect();
System.out.println("Results from query: \n");
if (rs.hasNext()) {
// show the result, more can be done here
System.out.println(ResultSetFormatter.asText(rs));
}
} catch (Exception e) {
System.out.print("Exception caught : ");
System.out.println(e.getMessage());
} finally {
qe.close();
}
System.out.println("All done.");
}
}